深入淺出MongoDB複製
原文轉貼自 http://mongoing.com/archives/5200







綜述
筆者最近在生產環境中遇到許多複製相關問題,查閱網上資料發現官方文檔雖然系統但是不夠有深度,網上部分深度文章則直接以源碼展示,不利於大家了解。所以本文則是結合前兩者最終給讀者以簡單的方式展現MongoDB複製的整個架構。本文分為以下5個步驟:
- MongoDB複製簡介
- MongoDB添加從庫
- MongoDB複製流程詳解
- MongoDB高可用
- MongoDB複製總結
1、MongoDB複製簡介
本章節首先會給大家簡單介紹一些MongoDB複製的一些基本概念,便於大家對後面內容的理解。
1.1、基本介紹
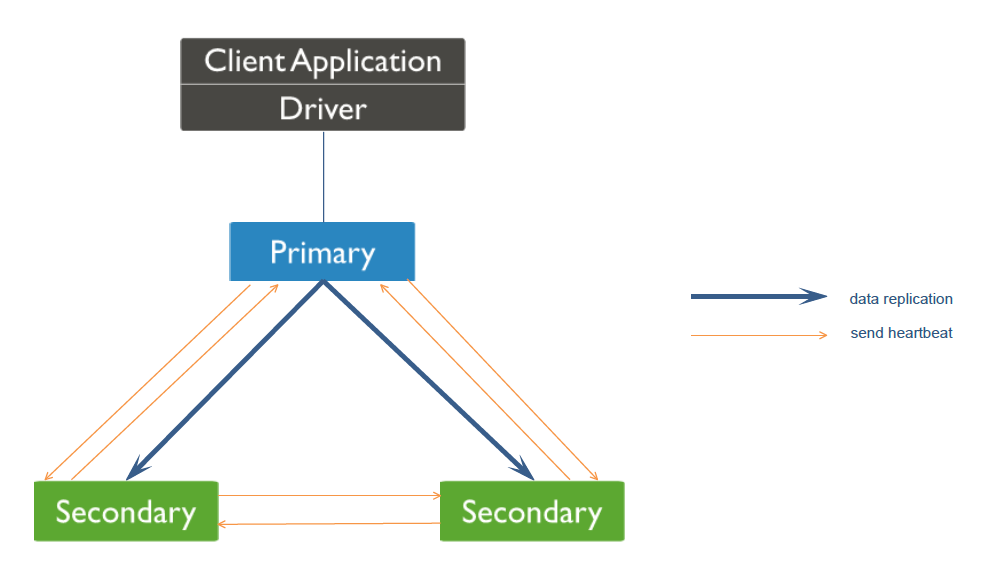
MongoDB有副本集及主從複製兩種模式,今天給大家介紹的是副本集模式,因為主從模式在MongoDB 3.6也徹底廢棄不使用了。MongoDB副本集有Primary、Secondary、Arbiter三種角色。今天給大家介紹的是Primary與Secondary數據同步的內部原理。MongoDB副本集架構如下所示:

1.2、MongoDB Oplog
MongoDB Oplog是MongoDB Primary和Secondary在複製建立期間和建立完成之後的複製介質,就是Primary中所有的寫入操作都會記錄到MongoDB Oplog中,然後從庫會來主庫一直拉取Oplog並應用到自己的數據庫中。這裡的Oplog是MongoDB local數據庫的一個集合,它是Capped collection,通俗意思就是它是固定大小,循環使用的。如下圖:

MongoDB Oplog中的內容及字段介紹:
{
"ts" : Timestamp(1446011584, 2),
"h" : NumberLong("1687359108795812092"),
"v" : 2,
"op" : "i",
"ns" : "test.nosql",
"o" : { "_id" : ObjectId("563062c0b085733f34ab4129"), "name" : "mongodb", "score" : "100" }
}
ts: 操作时间,當前timestamp + 計數器,計數器每秒都被重置
h:操作的全局唯一標誌
v:oplog版本信息
op:操作類型
i:插入操作
u:更新操作
d:删除操作
c:執行命令(如createDatabase,dropDatabase)
n:空操作,特殊用途
ns:操作針對的集合
o:操作内容,如果是更新操作
o2:操作查詢條件,僅update操作包含該字段
1.3、MongoDB複製發展
MongoDB目前已經疊代了很多個版本,下圖我匯總了目前市面上常用版本中MongoDB在複製的一些重要改進。

具體細節大家可以參考MongoDB官方Release Note:https://docs.mongodb.com/manual/release-notes/3.6/
2、MongoDB添加從庫
2.1、添加從庫命令
MongoDB添加從庫比較簡單,在安裝從庫之後,直接在主庫執行rs.add()或者replSetReconfig命令即可添加,這兩個命令其實在最終都調用replSetReconfig命令執行。大家有興趣可以去翻閱MongoDB客戶端JS代碼。
2.2、具體步驟
然後我們來看副本集加一個新從庫的大致步驟,如下圖,右邊的Secondary是我新加的從庫。

通過上圖我們可以看到一共有7個步驟,下面我們看看每一個步驟MongoDB都做了什麼:
1、主庫收到添加從庫命令
2、主庫更新副本集配置並與新從庫建立心跳機制
3、從庫收到主庫發送過來的心跳消息與主庫建立心跳
4、其他從庫收到主庫發來的新版本副本集配置信息並更新自己的配置
5、其他從庫與新從庫建立心跳機制
6、新從庫收到其他從庫心跳信息並跟其他從庫建立心跳機制
7 、新加的節點將副本集配置信息更新到local.system.replset集合中,MongoDB會在一個循環中查詢local.system.replset是否配置了replset信息,一旦查到相關信息觸發開啟複製線程,然後判斷是否需要全量複製,需要的話走全量複製,不需要走增量複製。
8、最終同步建立完成
2、主庫更新副本集配置並與新從庫建立心跳機制
3、從庫收到主庫發送過來的心跳消息與主庫建立心跳
4、其他從庫收到主庫發來的新版本副本集配置信息並更新自己的配置
5、其他從庫與新從庫建立心跳機制
6、新從庫收到其他從庫心跳信息並跟其他從庫建立心跳機制
7 、新加的節點將副本集配置信息更新到local.system.replset集合中,MongoDB會在一個循環中查詢local.system.replset是否配置了replset信息,一旦查到相關信息觸發開啟複製線程,然後判斷是否需要全量複製,需要的話走全量複製,不需要走增量複製。
8、最終同步建立完成
注意:
副本集所有節點之前都有相互的心跳機制,每2秒一次,在MongoDB 3.2版本以後我們可以通過heartbeatIntervalMillis參數來控制心跳頻率。
上述過程大家可以結合副本集節點狀態來看(rs.status命令):
- STARTUP //在副本集每個節點啟動的時候,mongod加載副本集配置信息,然後將狀態轉換為STARTUP2
- STARTUP2 //加載配置之後決定是否需要做Initial Sync,需要則停留在STARTUP2狀態,不需要則進入RECOVERING狀態
- RECOVERING //處於不可對外提供讀寫的階段,主要在Initial Sync之後追增量數據時候。
3、 MongoDB複製流程詳解
上面我們知道添加一個從庫的大致流程,那我們現在來看主從數據同步的具體細節。當從庫加入到副本集的時候,會判斷自己是需要Initial Syc(全量同步)還是增量同步。那是通過什麼條件判斷的呢?
3.1、判斷全量同步及增量同步
- 如果local數據庫中的oplog.rs 集合是空的,則做全量同步。
- 如果minValid集合裡面存儲的是_initialSyncFlag,則做全量同步(用於init sync失敗處理)
- 如果initialSyncRequested是true,則做全量同步(用於resync命令,resync命令只用於master/slave架構,副本集無法使用)
以上三個條件有一個條件滿足就需要做全量同步。
我們可以得出在從庫最開始加入到副本集的時候,只能先進行Initial Sync,下面我們來看看Initial Sync的具體流程
3.2、全量同步流程(Init sync)
3.2.1、 尋找同步源
這裡先說明一點,MongoDB默認是採取級聯複製的架構,就是默認不一定選擇主庫作為自己的同步源,如果不想讓其進行級聯複製,可以通過chainingAllowed參數來進行控制。在級聯複製的情況下,你也可以通過replSetSyncFrom命令來指定你想複製的同步源。所以這裡說的同步源其實相對於從庫來說就是它的主庫。那麼同步源的選取流程是怎樣的呢?
MongoDB從庫會在副本集其他節點通過以下條件篩選符合自己的同步源。
- 如果設置了chainingAllowed 為false,那麼只能選取主庫為同步源
- 找到與自己ping時間最小的並且數據比自己新的節點(在副本集初始化的時候,或者新節點加入副本集的時候,新節點對副本集的其他節點至少ping兩次)
- 該同步源與主庫最新optime做對比,如果延遲主庫超過30s,則不選擇該同步源。
- 在第一次的過濾中,首先會淘汰比自己數據還舊的節點。如果第一次沒有,那麼第二次需要算上這些節點,防止最後沒有節點可以做為同步源了。
- 最後確認該節點是否被禁止參與選舉,如果是則跳過該節點。
通過上述篩選最後過濾出來的節點作為新的同步源。
其實MongoDB同步源在除了在Initial Sync和增量複製的時候選定之後呢,並不是一直是穩定的,它可能在以下情況下進行變更同步源:
- ping不通自己的同步源
- 自己的同步源角色發生變化
- 自己的同步源與副本集任意一個節點延遲超過30s
3.2.2、 刪除MongoDB中除local以外的所有數據庫
3.2.3、 拉取主庫存量數據
這裡就到了Initial Sync的核心邏輯了,我下面以圖和步驟的方式給大家展現MongoDB在做Initial Sync的具體流程。

注:本圖是針對於MongoDB 3.4之前的版本
同步流程如下:
* 0. Add _initialSyncFlag to minValid collection to tell us to restart initial sync if we crash in the middle of this procedure
* 1. Record start time.(記錄當前主庫最近一次oplog time)
* 2. Clone.
* 3. Set minValid1 to sync target's latest op time.
* 4. Apply ops from start to minValid1, fetching missing docs as needed.(Apply Oplog 1)
* 5. Set minValid2 to sync target's latest op time.
* 6. Apply ops from minValid1 to minValid2.(Apply Oplog 2)
* 7. Build indexes.
* 8. Set minValid3 to sync target's latest op time.
* 9. Apply ops from minValid2 to minValid3.(Apply Oplog 3)
10. Cleanup minValid collection: remove _initialSyncFlag field, set ts to minValid3 OpTime
注:以上步驟直接copy的MongoDB源碼中的註釋。
* 0. Add _initialSyncFlag to minValid collection to tell us to restart initial sync if we crash in the middle of this procedure
* 1. Record start time.(記錄當前主庫最近一次oplog time)
* 2. Clone.
* 3. Set minValid1 to sync target's latest op time.
* 4. Apply ops from start to minValid1, fetching missing docs as needed.(Apply Oplog 1)
* 5. Set minValid2 to sync target's latest op time.
* 6. Apply ops from minValid1 to minValid2.(Apply Oplog 2)
* 7. Build indexes.
* 8. Set minValid3 to sync target's latest op time.
* 9. Apply ops from minValid2 to minValid3.(Apply Oplog 3)
10. Cleanup minValid collection: remove _initialSyncFlag field, set ts to minValid3 OpTime
注:以上步驟直接copy的MongoDB源碼中的註釋。
以上步驟在Mongo 3.4 Initial Sync 有如下改進:
- 在創建的集合的時候同時創建了索引(與主庫一樣),在MongoDB 3.4版本之前只創建_id索引,其他索引等待數據copy完成之後進行創建。
- 在創建集合和拷貝數據的同時,也將oplog拷貝到本地local數據庫中,等到數據拷貝完成之後,開始應用本地oplog數據。
- 新增由於網絡問題導致Initial Sync 失敗重試機制。
- 在Initial Sync期間發現collection 重命名了會重新開始Initial Sync。
上述4個新增特性提升了Initial Sync的效率並且提高了Initial Sync的可靠性,所以大家使用MongoDB最好使用最新版本MongoDB 3.4或者3.6,MongoDB 3.6更是有一些令人興奮的特性,這裡就不在此敘述了。
全量同步完成之後,然後MongoDB會進入到增量同步的流程。
全量同步完成之後,然後MongoDB會進入到增量同步的流程。
3.3、增量同步流程
上面我們介紹了Initial Sync,就是已經把同步源的存量數據拿過來了,那主庫後續寫入的數據怎麼同步過來呢?下面還是以圖跟具體的步驟來給大家介紹:

注:這裡不一定是Primary,剛剛提到了同步源也可能是Secondary,這裡採用Primary主要方便大家理解。
我們可以看到上述有6個步驟,那每個步驟具體做的事情如下:
1、 Sencondary初始化同步完成之後,開始增量複製,通過produce線程在Primary oplog.rs集合上建立cursor,並且實時請求獲取數據。
2、 Primary返回oplog數據給Secondary。
3、 Sencondary讀取到Primary發送過來的oplog,將其寫入到隊列中。
4、 Sencondary的同步線程會通過tryPopAndWaitForMore方法一直消費隊列,當每次達到一定的條件之後,條件如下:
2、 Primary返回oplog數據給Secondary。
3、 Sencondary讀取到Primary發送過來的oplog,將其寫入到隊列中。
4、 Sencondary的同步線程會通過tryPopAndWaitForMore方法一直消費隊列,當每次達到一定的條件之後,條件如下:
- 總數據大於100MB
- 已經取到部分數據但沒到100MB,但是目前隊列沒數據了,這個時候會阻塞等待一秒,如果還沒有數據則本次取數據完成。
上述兩個條件滿足一個之後,就會將數據給prefetchOps方法處理,prefetchOps方法主要將數據以database級別切分,便於後面多線程寫入到數據庫中。如果採用的WiredTiger引擎,那這裡是以Docment ID 進行切分。
5、最終將劃分好的數據以多線程的方式批量寫入到數據庫中(在從庫批量寫入數據的時候MongoDB會阻塞所有的讀)。
6、然後再將Queue中的Oplog數據寫入到Sencondary中的oplog.rs集合中。
6、然後再將Queue中的Oplog數據寫入到Sencondary中的oplog.rs集合中。
4、 MongoDB高可用
上面我們介紹MongoDB複製的數據同步,我們知道除了數據同步,複製還有一個重要的地方就是高可用,一般的數據庫是需要我們自己去定制方案或者採用第三方的開源方案。MongoDB則是自己在內部已經實現了高可用方案。下面我就給大家詳細介紹一下MongoDB的高可用。
4.1、觸發切換場景
首先我們看那些情況會觸發MongoDB執行主從切換。
1、新初始化一套副本集
2、從庫不能連接到主庫(默認超過10s,可通過heartbeatTimeoutSecs參數控制),從庫發起選舉
3、主庫主動放棄primary角色
2、從庫不能連接到主庫(默認超過10s,可通過heartbeatTimeoutSecs參數控制),從庫發起選舉
3、主庫主動放棄primary角色
- 主動執行rs.stepdown 命令
- 主庫與大部分節點都無法通信的情況下
- 修改副本集配置的時候(在Mongo 2.6版本會觸發,其他版本待確定)
修改以下配置的時候:
- _id
- votes
- priotity
- arbiterOnly
- slaveDelay
- hidden
- buildIndexes
4、 移除從庫的時候(在MongoDB 2.6會觸發,MongoDB 3.4不會,其他版本待確定)
4.2、心跳機制
通過上面觸發切換的場景,我們了解到MongoDB的心跳信息是MongoDB判斷對方是否存活的重要條件,當達到一定的條件時,MongoDB主庫或者從庫就會觸發切換。下面我給大家詳細介紹一下心跳機制,MongoDB 副本集心跳機製圖如下:

我們知道MongoDB副本集所有節點都是相互保持心跳的,然後心跳頻率默認是2秒一次,也可以通過heartbeatIntervalMillis來進行控制。在新節點加入進來的時候,副本集中所有的節點需要與新節點建立心跳,那心跳信息具體是什麼內容呢?
心跳信息內容:
BSONObjBuilder cmdBuilder;
cmdBuilder.append("replSetHeartbeat", setName);
cmdBuilder.append("v", myCfgVersion);
cmdBuilder.append("pv", 1);
cmdBuilder.append("checkEmpty", checkEmpty);
cmdBuilder.append("from", from);
if (me > -1) {
cmdBuilder.append("fromId", me);
}
注:上述代碼摘抄MongoDB 源碼中構建心跳信息片段。
具體在MongoDB日誌中表現如下:
command admin.$cmd command: replSetHeartbeat { replSetHeartbeat: "shard1", v: 21, pv: 1, checkEmpty: false, from: "10.13.32.244:40011", fromId: 3 } ntoreturn:1 keyUpdates:0
那副本集所有節點默認都是每2秒給其他剩餘的節點發送上述信息,在其他節點收到信息後會調用ReplSetCommand命令來處理心跳信息,處理完成會返回如下信息:
result.append("set", theReplSet->name());
MemberState currentState = theReplSet->state();
result.append("state", currentState.s); // 當前節點狀態
if (currentState == MemberState::RS_PRIMARY) {
result.appendDate("electionTime", theReplSet->getElectionTime().asDate());
}
result.append("e", theReplSet->iAmElectable()); //是否可以參與選舉
result.append("hbmsg", theReplSet->hbmsg());
result.append("time", (long long) time(0));
result.appendDate("opTime", theReplSet->lastOpTimeWritten.asDate());
const Member *syncTarget = replset::BackgroundSync::get()->getSyncTarget();
if (syncTarget) {
result.append("syncingTo", syncTarget->fullName());
}
int v = theReplSet->config().version;
result.append("v", v);
if( v > cmdObj["v"].Int() )
result << "config" <config().asBson();
注:以上信息是正常情況下返回的,還有一些不正常的處理場景,這裡就不一一細說了。
4.3、切換流程
前面我們了解了觸發切換的場景以及MongoDB副本集節點之前的心跳機制。下面我們來看切換的具體流程:
1、從庫無法連接到主庫,或者主庫放棄Primary角色。
2、從庫會根據心跳消息獲取當前該節點的角色並與之前進行對比
3、如果角色發生改變就開始執行msgCheckNewState方法
4、在msgCheckNewState方法中最終調用electSelf方法(會有一些判斷來決定是否最終調用electSelf方法)
5、electSelf方法最終向副本集其他節點發送replSetElect命令來請求投票。
命令如下:
1、從庫無法連接到主庫,或者主庫放棄Primary角色。
2、從庫會根據心跳消息獲取當前該節點的角色並與之前進行對比
3、如果角色發生改變就開始執行msgCheckNewState方法
4、在msgCheckNewState方法中最終調用electSelf方法(會有一些判斷來決定是否最終調用electSelf方法)
5、electSelf方法最終向副本集其他節點發送replSetElect命令來請求投票。
命令如下:
BSONObj electCmd = BSON(
"replSetElect" << 1 <<
"set" << rs.name() <<
"who" << me.fullName() <<
"whoid" << me.hbinfo().id() <<
"cfgver" <version <<
"round" << OID::gen() /* this is just for diagnostics */
);
具體日誌表現如下:
2017-12-14T10:13:26.917+0800 [conn27669] run command admin.$cmd { replSetElect: 1, set: “shard1″, who: “10.13.32.244:40015″, whoid: 4, cfgver: 27, round : ObjectId('5a31de4601fbde95ae38b4d2′) }
6、其他副本集收到replSetElect會對比cfgver信息,會確認發送該命令的節點是否在副本集中,確認該節點的優先級是否是該副本集所有節點中優先級最大的。最後滿足條件才會給該節點發送投票信息。
7、發起投票的節點最後會統計所得票數大於副本集可參與投票數量的一半,則搶占成功,成為新的Primary。
8、其他從庫如果發現自己的同步源角色發生變化,則會觸發重新選取同步源。
7、發起投票的節點最後會統計所得票數大於副本集可參與投票數量的一半,則搶占成功,成為新的Primary。
8、其他從庫如果發現自己的同步源角色發生變化,則會觸發重新選取同步源。
4.4、Rollback
我們知道在發生切換的時候是有可能造成數據丟失的,主要是因為主庫宕機,但是新寫入的數據還沒有來得及同步到從庫中,這個時候就會發生數據丟失的情況。
那針對這種情況,MongoDB增加了回滾的機制。在主庫恢復後重新加入到複製集中,這個時候老主庫會與同步源對比oplog信息,這時候分為以下兩種情況:
1、在同步源中沒有找到比老主庫新的oplog信息。
2、同步源最新一條oplog信息跟老主庫的optime和oplog的hash內容不同。
1、在同步源中沒有找到比老主庫新的oplog信息。
2、同步源最新一條oplog信息跟老主庫的optime和oplog的hash內容不同。
針對上述兩種情況MongoDB會進行回滾,回滾的過程就是逆向對比oplog的信息,直到在老主庫和同步源中找到對應的oplog,然後將這期間的oplog全部記錄到rollback目錄裡的文件中,如果但是出現以下情況會終止回滾:
- 對比老主庫的optime和同步源的optime,如果超過了30分鐘,那麼放棄回滾。
- 在回滾的過程中,如果發現單條oplog超過512M,則放棄回滾。
- 如果有dropDatabase操作,則放棄回滾。
- 最終生成的回滾記錄超過300M,也會放棄回滾。
上述我們已經知道了MongoDB的回滾原理,但是我們在生產環境中怎麼避免回滾操作呢,因為畢竟回滾操作很麻煩,而且針對有時序性的業務邏輯也是不可接受的。那MongoDB也提供了對應的方案,就是WriteConcern,這裡就不細說了,有興趣的朋友可以仔細了解。其實這也是在CAP中做出一個選擇。
5、 MongoDB複製總結
MongoDB複製內部原理已經給大家介紹完畢,以上其實還涉及很多細節沒能一一列出。大家有興趣可以自己去整理。這裡還需要說明一點就是MongoDB版本疊代速度比較快,所以本文只針對於MongoDB 2.6 到MongoDB 3.4 版本,不過在某些版本可能會存在一些細節的變動,但是大體上的邏輯還是沒有改變。最後大家如果有什麼問題,也可以與我聯繫。
個人簡介
趙景波,3年專職DBA經驗,2017 DTCC 講師,CRUG用戶組成員,目前主要負責新浪NoSQL服務的運維及研發工作。熱衷於開源DB內部原理探究。

{kind=link}
{kind=link}
留言
張貼留言
歡迎您留下寶貴的意見,鼓勵小編~~